
Nowadays Azure Synapse is one of the hottest topics in the data industry. But what it really is and what it can offer to business? In this post, we will address these questions.
Azure Synapse analytics is a limitless analytics service that brings together data integration, data exploration, data warehouse, and big data analytics. This unified platform combines the needs of data engineering, machine learning, and business intelligence without the need to maintain separate tools and processes.
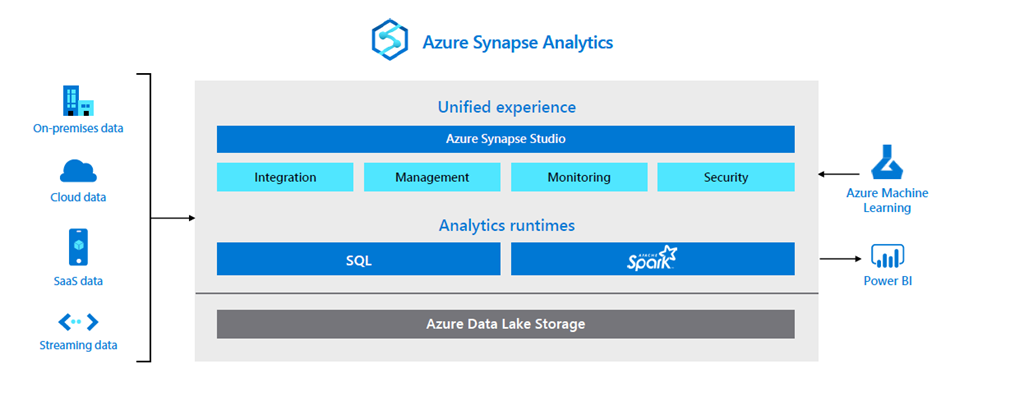
Current version is evolution of Azure SQL Data Warehouse product, developing by Microsoft since 2016. Core and crucial difference between SQL Data Warehouse and SQL Database was to split compute and storage: data is filled in a filesystem and compute is used only when is required with massive parallel processing scaling. This solution is still part of Synapse environment as dedicated SQL pool. However, Microsoft introduced much more features to that which bring this tool to a new level.
Now that we understand platform overview let’s focus on key capabilities of Azure Synapse.
Azure Synapse – Capabilities
It offers unified analytics experience available through Synapse Studio. This tool allows developers to dive into all platform aspects from a single interface. Features like data ingestion, using import tool or data pipelines (powered by Azure Data Factory), data flow creation, data exploration using notebooks or SQL scripts or finally data visualization are available in one place. Naturally workload monitoring and performance optimization are part of the package.
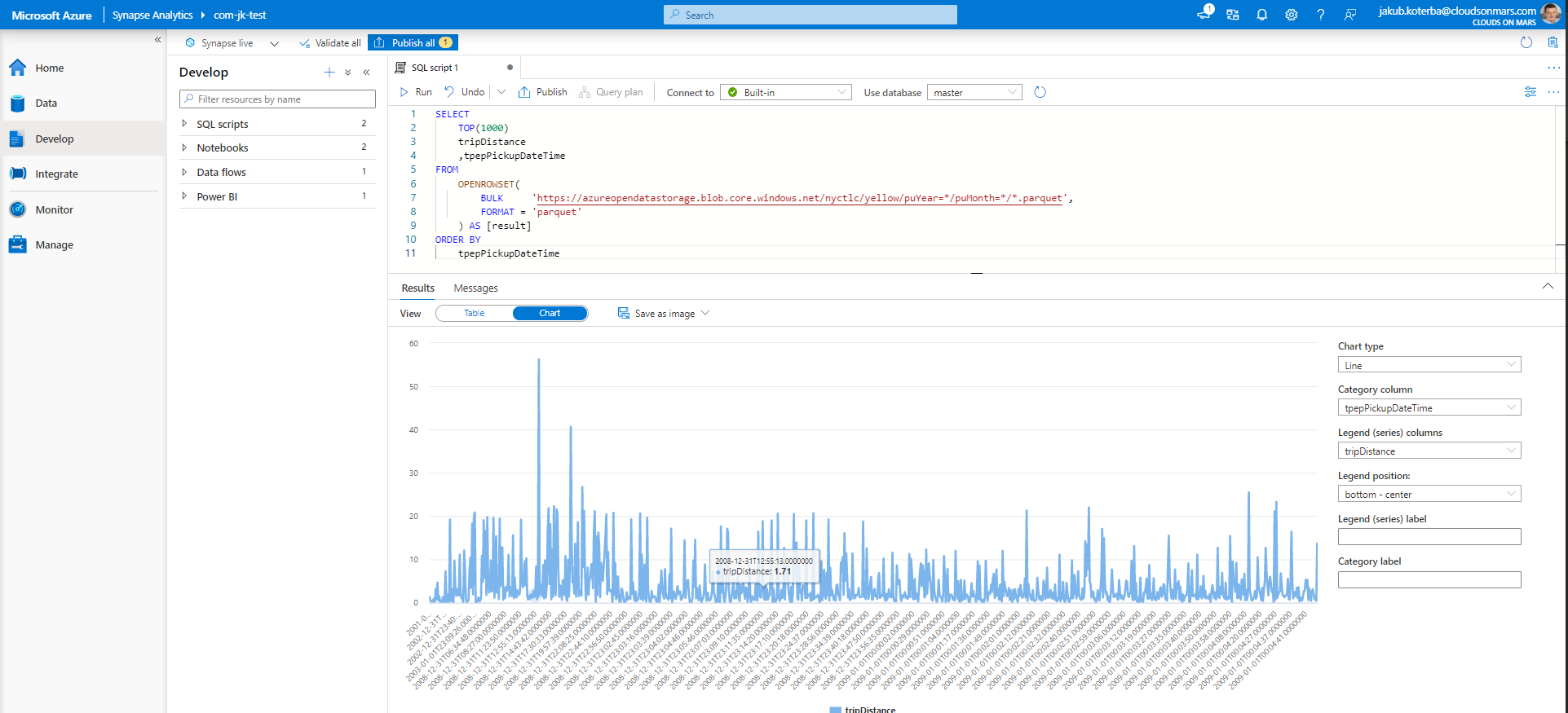
Azure Synapse offer consumption choice for querying both relational and non-relational data using the familiar SQL language. This can be done using either serverless on-demand queries for ad hoc data analysis and exploration or using provisioned resources (dedicated SQL pool) for predictable and demanding data warehouse needs.
- Serverless SQL pool can query external files stored in Azure storage without need to copy or load data to other location using T-SQL dialect. By default, this service is provided within every Synapse workspace so it can be used as soon as workspace is created. As name suggest with this approach there is no infrastructure to maintain and also no cost for keeping service alive. This service follows pay-per-use pricing model, so costs are charged only for the data processed by queries. Costs can be controlled by using budget limits for amount of data used (TB) in day, week or month.
- Dedicated SQL pool is a choice for enterprise data warehousing. Data is stored in tables with columnar storage which significantly improve performance and reducing costs. It’s also used massive parallel processing architecture to run queries. This service is not enabled by default in Azure Synapse Analytics. Required is to create appropriate pool, manually selecting relevant performance level which can be change later on. Dedicated pool is charged per hour, but cost can be controlled by scaling service up and down when needed but also offer option to pause pool when it’s not used.
These are not the only options. Moreover, in Azure Synapse Apache Spark pools are available. This service is one of the most favorite tool for data engineers and data scientists thanks to handling extensive amount of data and machine learning capabilities. Having that incorporated in Azure Synapse it can leverage fully managed provisioning, incorporated security and integration with other Azure components like Azure Key Vault, ADLS Gen 2, blob storage or SQL databases (dedicated and serverless). Similar to dedicated pool, Apache Spark is charged by cost per hour, which is also related to selected node size, but also offer scaling and auto pause option.
To orchestrate all these resources and services Synapse suite include integrate module. It inherited most of the Azure Data Factory data integration components. For those who are not familiar with ADF, it’s a serverless data integration solution for ingesting, preparing and transforming data. It offers wide variety of data source connectors. Furthermore, over standard ADF features, integrate module introduce new components to use Apache Spark pool (running notebooks and Spark job definition) and also to run SQL pool stored procedure.
Additional features
Except all these core functionalities Azure Synapse Analytics include much more features:
- Data lake exploration. For some file format, analyze of data was not always easy or required some additional tools. For example, Parquet files, which are highly compressed, are great to store but a bit cumbersome to read. With Synapse we can right click on the file and open it using SQL script
- Choice of language. Depending on preferences users can select from T-SQL, Python, Scala, Spark SQL or .Net used for serverless or dedicated resources.
- Resource management and monitoring. Platform offer wide range of industry leading compliance and security features. Users can use single-sign-on with Azure Active Directory integration.
- Delta lake support. Platform is compatible with Linux Foundation Delta Lake. It’s open-source storage layer which offer ACID transactions (atomicity, consistency, isolation, durability) to Apache Spark and big data workloads. Additionally, it includes time travel (data versioning) feature and handle scalable metadata.
- Azure Synapse Pathway. It’s a tool which help to simplify and accelerate migration for both on-premises and cloud data warehouse to Azure Synapse analytics. It connects to source system and inspect details about database objects and provide assessment report. After that tool convert and optimize objects to T-SQL code on Azure Synapse Analytics.
Azure Synapse Analytics platform enables to accelerate time to insight with a unified analytical experience which allow to save costs. Thanks to intelligent architecture, which separate storage and compute resource it’s cost-effective service. This offers huge flexibility for business. Starting from the small proof of concept project environment can be scaled to production size. Also, if there will be such need, resources can be paused to limit cost. This unified environment delivers all tools required for data engineers and data scientist in one place.
Read our article on migrating to the cloud with Azure.