

by Artur Gierej
Data lakehouse architecture is a modern approach to building data warehousing systems. It utilizes the standard data warehousing approach, and combines it with all the advantages of data lake. Typical data warehouses were introduced in the 1980s. They were designed to handle large data sizes, providing the possibility to store structured data, optimized for analytics. However, while data warehouses were great for storing and processing of structured data, today lots of companies have to deal with unstructured or semi-structured data with high variety, velocity and volume. Data warehouses were not fully suited for these needs, and – for sure – were not the most cost efficient.
The need to store and process unstructured data led to the invention of data lakes – repositories for raw data in a variety of formats. Data lakes proved to be a good solution for storing unstructured data, but there was a problem with supporting transactions, enforcement of data quality, and lack of consistency. Therefore data lakes lead to a loss of many benefits of standard data warehouses. The need for a flexible, high-performance system enforced a new approach and finally led to the introduction of the Data Lakehouse concept.
Data Lakehouse – whats is it?
A data lakehouse is a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of data warehouses, enabling business intelligence (BI) and machine learning (ML) on all data. Data lakehouses implement data warehouses’ data structures and management features for data lakes, which are typically more cost-effective for data storage.
The diagram below compares data warehouse, data lake and data lakehouse architectures.
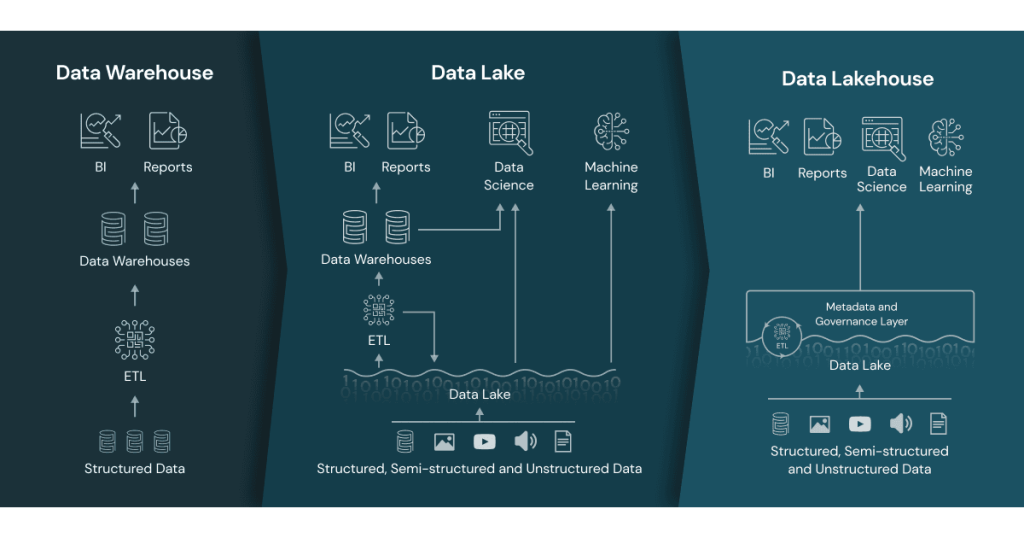
Data Lakehouses represent a new, modern design. They implement similar data structures and data management features to the ones in a data warehouse, however it is all built on top of low-cost storage in open formats.
The main features of Data Lakehouse include:
- transaction support
- schema enforcement and governance
- BI support (we can build BI tools directly on top of source data)
- storage is decoupled from compute
- openness (usage of open format like parquet files, and providing an API for a variety of tools like Python/R/etc.)
- support for diverse workloads (they all rely on the same repository)
- end-to-end streaming (that allows to build real-time applications)
Commercial Data Lakehouse solutions leveraging DataBricks tool are available on all main cloud platforms: Azure, AWS, and GCP
Why do organizations use Data Lakehouse?
A data lakehouse concept can help organizations move past the limitations of data warehouses and data lakes. It lets them reach a middle ground where they can get the best of both worlds in terms of data storage and data management.
They get data warehouse features and data structures with the flexibility of data lakes.
Apart from that, this solution is very cost-effective compared to standard data warehousing implementations.
From the organizational point of view flexibility is one of the key advantages. They are allowed to process both structured as well as semi-structured and unstructured data, and to use it for many different purposes like: standard Data Analytics and Business Intelligence, Machine Learning, Artificial Intelligence, or Real-Time data streaming.
Another advantage is the possibility to customize the solution using typical programming languages like Python or R.
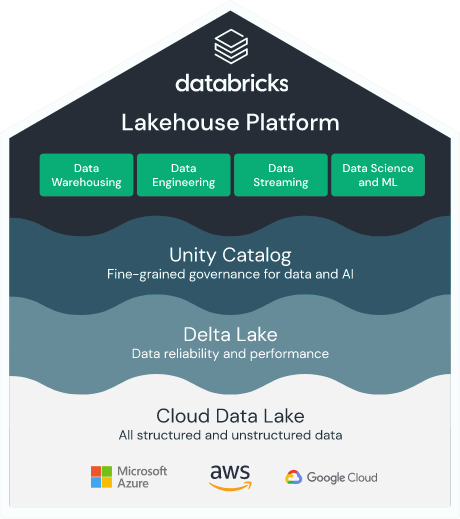
Data Lakehouse challenges
The main challenge of building Data Lakehouse is the implementation part. To be able to do so you need to have advanced skills in tools like DataBricks. You should also have vast knowledge regarding specific cloud platform architecture.
The next challenge might be Management Difficulty. Even for skilled engineers, data lakehouses can be sometimes hard to manage.
Benefits of a Data Lakehouse
Like mentioned before, data lakehouse inherit all the benefits of data warehouses, with addition of all the benefits taken from data lake approach. Below you can find the list of most important ones.
Cost effective data storage
Compared to standard data warehouses, data lakehouses are very cost-effective, especially thanks to low-cost storage. That can optimize your implementation and maintenance costs.
Direct access to data for analyzing tools
You can easily access data at different levels. Thanks to the multi-layer architecture you can use both raw data, as well as cleansed or fully structured data.
Simplified schema and data governance
Compared to standard data warehouses schema is much more simplified, and therefore easy to govern.
Variety of potential usages
Data Lakehouses offer standard data warehouse capabilities like Data Analytics and building BI-tools, combined with Data Science features like ML or AI. Apart from that they are also great for real-time data streaming purposes.
What are the layers of a Data Lakehouse?
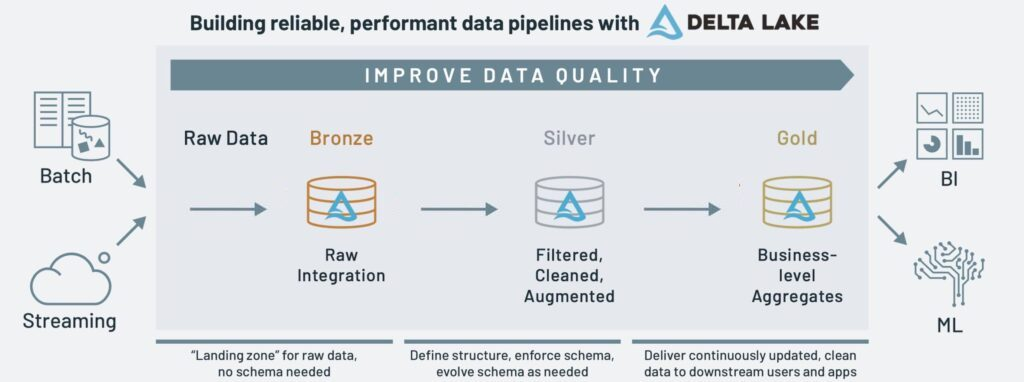
Medallion Architecture is one of data lakehouse design patterns. When deployed, it allows for simple data flow through specific data lakehouse layers. With each layer, data and its structure is augmented, enhanced, cleaned and aggregated to finally present end-users with high quality data products that may be used for Business Intelligence reporting and Machine Learning.
Different approaches to Medallion Architecture implementation can be encountered, with Databricks’ prime example of Bronze → Silver → Gold layers:
Alternatively, Microsoft’s example presents such layers as Raw → Enriched → Curated Layers:
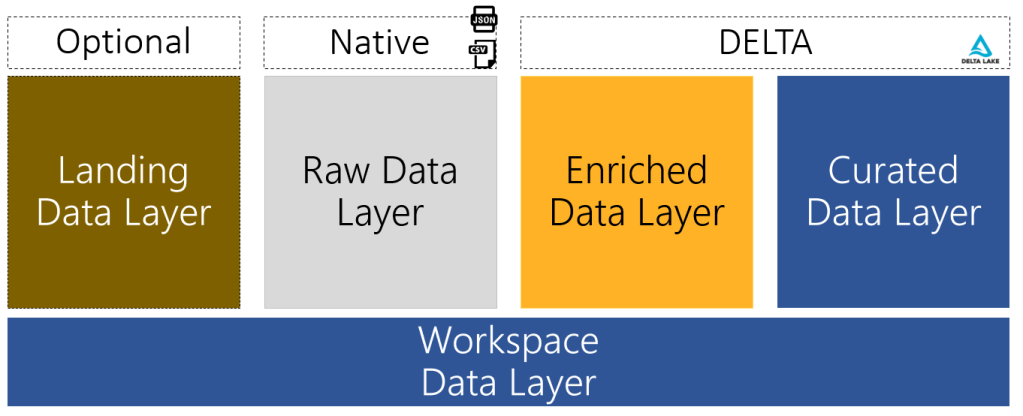
Raw Layer stores data extracted from source systems as is, which is then filtered out of impurities and enriched in the Enriched Layer with final, Curated Layer, being the consumption layer that’s optimized for analytics having data stored in de-normalized data marts and/or star schemas. Optionally, a Landing Layer may appear which can be treated as a dump for files before these are stored in an orderly fashion on Raw Layer.
Data Lakehouse Architecture – its purpose
Purpose of the Data Lakehouse architecture is to prepare reliable, flexible data storage, optimized for both storing and processing of high structured data, as well as semi-structured and unstructured data. At the same time it is very cost effective compared to standard data warehouses.
How do you make data lake architecture?
Developers preparing Data Lakehouse Framework should follow the Medallion Architecture during the implementation process.
Three separate layers need to be prepared according to best practices:
Raw Layer
Enriched Layer
Curated Layer
Each of those layers has a common data structure, characteristic for the specific zone for the ease of use and development.
With the utilized approach to implementation of the Data Lakehouse Framework, data from Enriched Layer can already be used for Data Science and Machine Learning, as it’s already schema-bound, cleaned and augmented. For standard business users, the Curated Layer should be used, as the data present in that Lake Zone is modeled into a star schema or specific data marts with lower entry level threshold to using it and having more value to be used in standard reporting when compared to Enriched Layer.
Finally, the data has a final meta layer applied on the Curated Layer, being data views. These are used to provide a final way of filtering unneeded data and ensure only business-specific columns for dimensions and facts when accessed by end users.
To acquire data from Databricks’ Curated Layer and access it with Power BI, SQL Endpoint is created that is cost optimized for querying data. Framework gives full control over Power BI Refreshes with its Databricks API and Power BI API implementations that allow for executing both SQL Endpoint run to prepare it for Power BI refresh as well as directly starting Power BI refresh for required datasets and dataflows on Power BI Service.
Final thoughts – why use Data Lakehouse architecture?
Data Warehouses were not able to meet modern requirements regarding processing of semi-structured and unstructured data. At the same time Data Lakes were not good for fully structured structures and transactional approach. Data Lakehouse concept allows to have benefits of those 2 approaches, without having a need to compromise. It’s flexibility and low costs make it a great architecture for advanced data processing, and combining standard data analytics on structured data, with Data Science techniques, and real time streaming approach. All these features make it a modern architecture meeting very demanding needs of modern enterprises.
You can also read about: